
 PhD Student, Nanjing University
PhD Student, Nanjing UniversityI am currently a lecturer at Nanjing University of Posts and Telecommunications. I received my Ph.D. in Software Engineering from the School of Computer Science, Nanjing University, in June 2025, under the supervision of Professor Qing Gu (顾庆) and Assistant Professor Zhiwei Jiang (蒋智威). My research focuses on multimodal video understanding and analysis.
👋 If you have opportunities in academia related to my research, please email me and I would be delighted to connect and explore potential collaborations!
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
Nanjing UniversitySchool of Computer Science
Ph.D. StudentSep. 2019 - Jun. 2025
Experience
-
 Tencent WeChatResearch InternMay. 2023 - Jan. 2025
Tencent WeChatResearch InternMay. 2023 - Jan. 2025 -
 Nanjing University of Posts and TelecommunicationsLecturerNov. 2025 - Present
Nanjing University of Posts and TelecommunicationsLecturerNov. 2025 - Present
Honors & Awards
-
Nomination Award for Outstanding Doctoral Dissertation of the School of Computer Science, Nanjing University2025
-
Outstanding Graduate of Nanjing University2025
-
Recognition Award of 2023 Tencent Rhino-Bird Research Elite Program2024
-
Yingcai Scholarship of Nanjing University, First Prize2024
-
Huawei Scholarship of Nanjing University2023
-
Outstanding Postgraduate Student of Nanjing University2023
Selected Publications (view all )
Implicit Location-Caption Alignment via Complementary Masking for Weakly-Supervised Dense Video Captioning
Shiping Ge, Qiang Chen, Zhiwei Jiang, Yafeng Yin, Qin Liu, Ziyao Chen, Qing Gu
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI Oral, CCF-A) 2025
We propose a novel implicit location-caption alignment paradigm based on complementary masking, which addresses the problem of unavailable supervision on event localization in the WSDVC task.
Implicit Location-Caption Alignment via Complementary Masking for Weakly-Supervised Dense Video Captioning
Shiping Ge, Qiang Chen, Zhiwei Jiang, Yafeng Yin, Qin Liu, Ziyao Chen, Qing Gu
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI Oral, CCF-A) 2025
We propose a novel implicit location-caption alignment paradigm based on complementary masking, which addresses the problem of unavailable supervision on event localization in the WSDVC task.
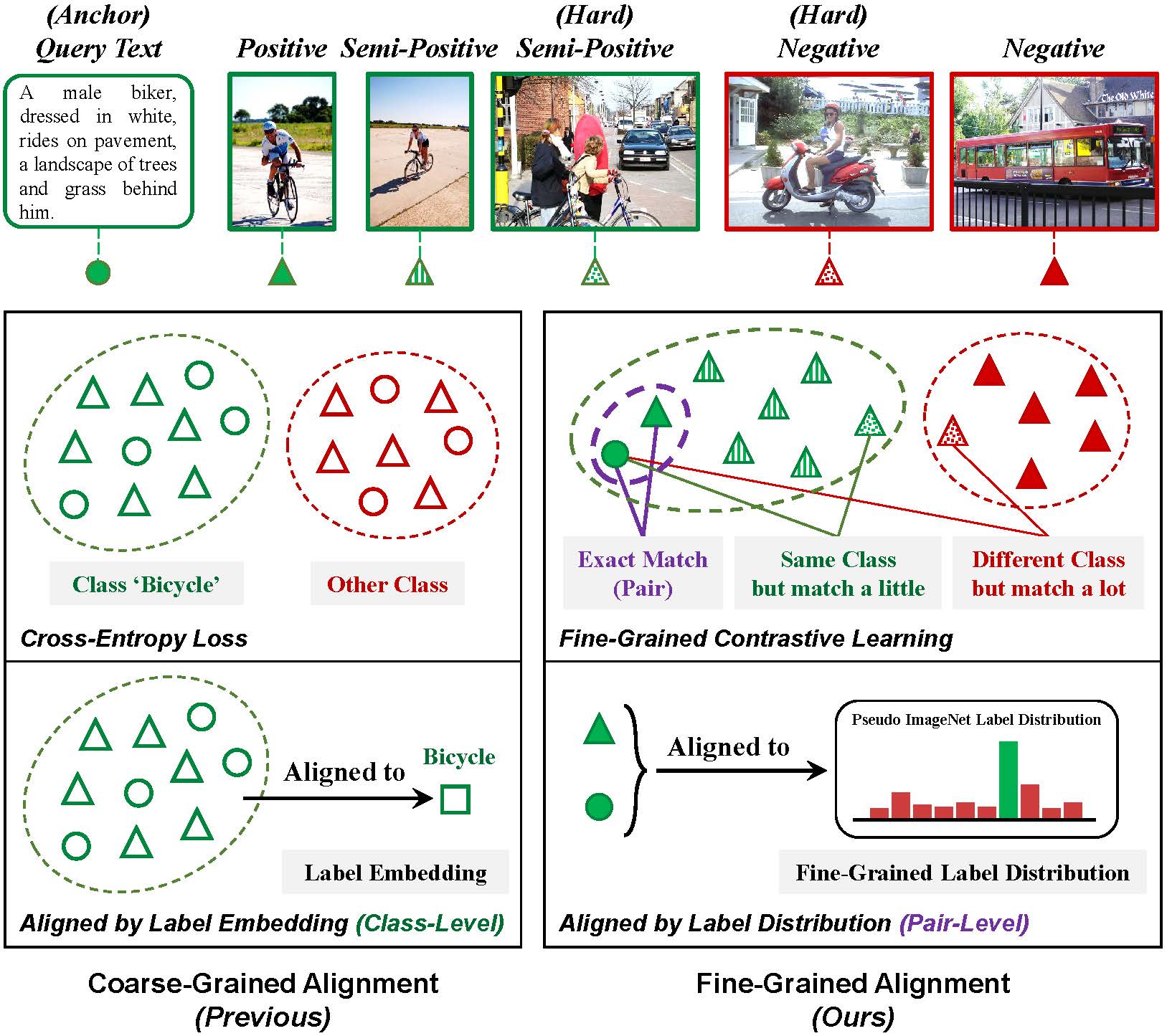
Fine-Grained Alignment Network for Zero-Shot Cross-Modal Retrieval
Shiping Ge, Zhiwei Jiang, Yafeng Yin, Cong Wang, Zifeng Cheng, Qing Gu
ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM, CCF-B) 2025
We propose a novel end-to-end ZS-CMR framework FGAN, which can learn fine-grained alignment-aware representation for data of different modalities.
Fine-Grained Alignment Network for Zero-Shot Cross-Modal Retrieval
Shiping Ge, Zhiwei Jiang, Yafeng Yin, Cong Wang, Zifeng Cheng, Qing Gu
ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM, CCF-B) 2025
We propose a novel end-to-end ZS-CMR framework FGAN, which can learn fine-grained alignment-aware representation for data of different modalities.

Short Video Ordering via Position Decoding and Successor Prediction
Shiping Ge, Qiang Chen, Zhiwei Jiang, Yafeng Yin, Ziyao Chen, Qing Gu
Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR, CCF-A) 2024
We introduce a novel Short Video Ordering (SVO) task, curate a dedicated multimodal dataset for this task and present the performance of some benchmark methods.
Short Video Ordering via Position Decoding and Successor Prediction
Shiping Ge, Qiang Chen, Zhiwei Jiang, Yafeng Yin, Ziyao Chen, Qing Gu
Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR, CCF-A) 2024
We introduce a novel Short Video Ordering (SVO) task, curate a dedicated multimodal dataset for this task and present the performance of some benchmark methods.
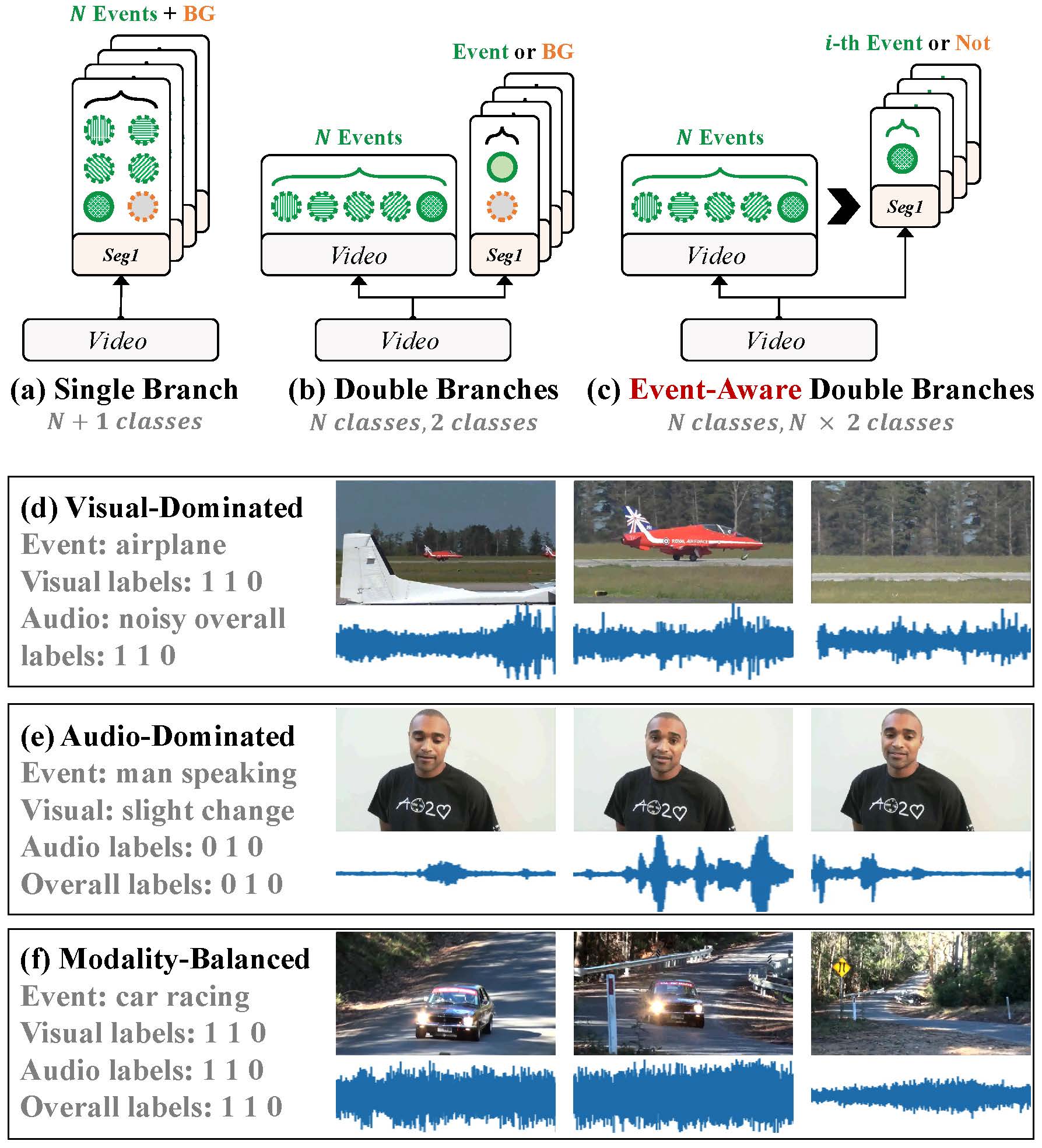
Learning Event-Specific Localization Preferences for Audio-Visual Event Localization
Shiping Ge, Zhiwei Jiang, Yafeng Yin, Cong Wang, Zifeng Cheng, Qing Gu
Proceedings of the 31st ACM International Conference on Multimedia (ACMMM, CCF-A) 2023
We propose a new event-aware double-branch localization paradigm to utilize event preferences for more accurate audio-visual event localization.
Learning Event-Specific Localization Preferences for Audio-Visual Event Localization
Shiping Ge, Zhiwei Jiang, Yafeng Yin, Cong Wang, Zifeng Cheng, Qing Gu
Proceedings of the 31st ACM International Conference on Multimedia (ACMMM, CCF-A) 2023
We propose a new event-aware double-branch localization paradigm to utilize event preferences for more accurate audio-visual event localization.
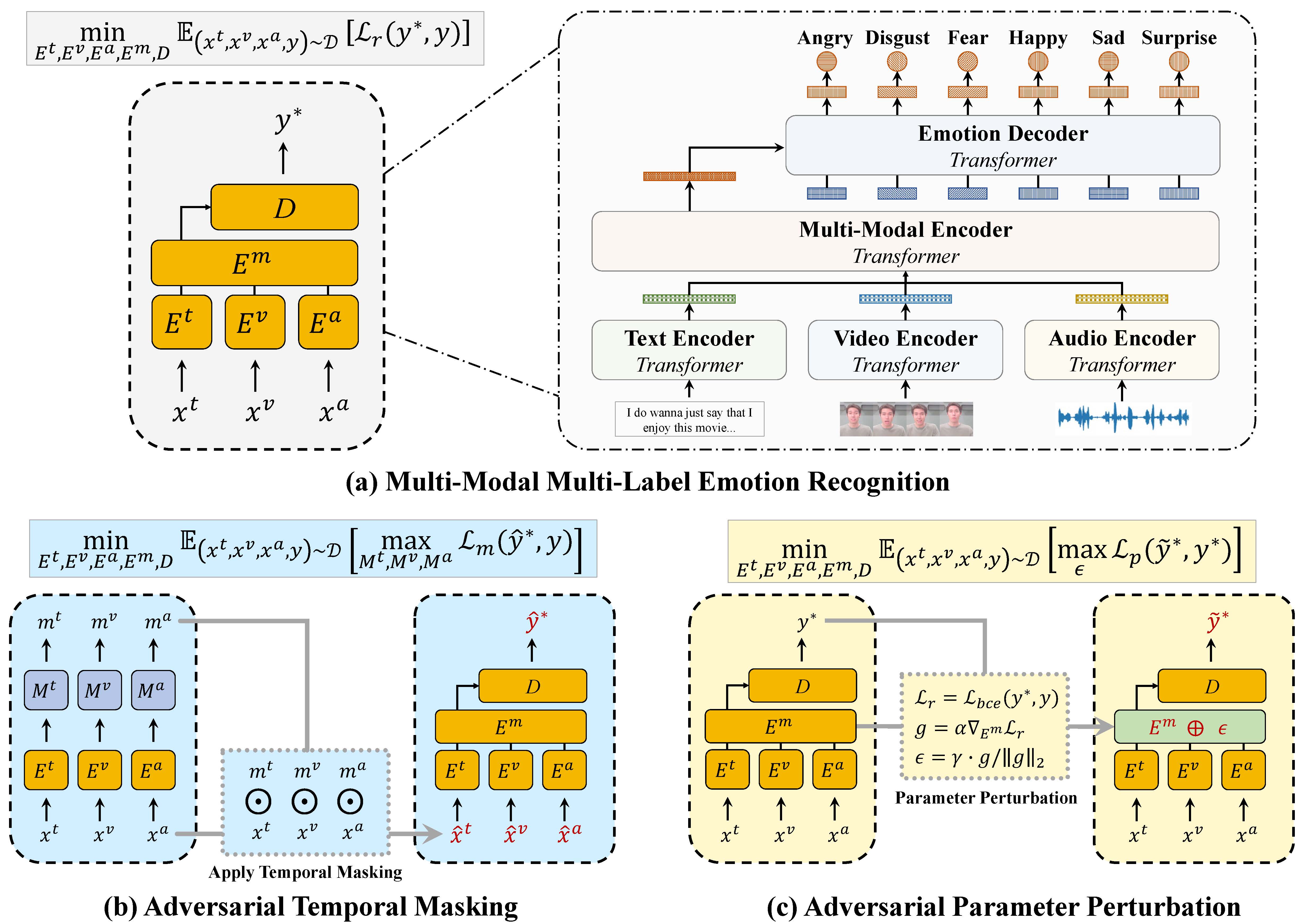
Learning Robust Multi-Modal Representation for Multi-Label Emotion Recognition via Adversarial Masking and Perturbation
Shiping Ge, Zhiwei Jiang, Cong Wang, Zifeng Cheng, Yafeng Yin, Qing Gu
Proceedings of the ACM Web Conference (WWW, CCF-A) 2023
We design a simple encoder-decoder style multi-modal emotion recognition model, and combine it with our specially-designed adversarial training strategies to learn more robust multi-modal representation for multi-label emotion recognition.
Learning Robust Multi-Modal Representation for Multi-Label Emotion Recognition via Adversarial Masking and Perturbation
Shiping Ge, Zhiwei Jiang, Cong Wang, Zifeng Cheng, Yafeng Yin, Qing Gu
Proceedings of the ACM Web Conference (WWW, CCF-A) 2023
We design a simple encoder-decoder style multi-modal emotion recognition model, and combine it with our specially-designed adversarial training strategies to learn more robust multi-modal representation for multi-label emotion recognition.